平台服务
数据挖掘与机器学习是什么关系?
知乎用户:AlgorithmDog
数据挖掘拥有很多定义, 其中一个比较有名的定义为 “一门从大量数据或者数据库中提取有用信息的科学”。大部分人是通过一个案例认识到数据挖掘:这是因为沃尔玛通过数据分析发现,男性顾客在购买婴儿尿片时,常常会顺便搭配几瓶啤酒来犒劳自己,于是尝试推出了将啤酒和尿布摆在一起的促销手段;没想到这个举措居然使尿布和啤酒的销量都大幅增加了。虽然这个故事很可能是假的(Teradata公司一位经理编出来的“故事”目的是让数据分析看起来更有力更有趣), 但是确实让不少人开始接触数据挖掘。我们似乎能感受数据挖掘的企图心:从数据出发,建立一个类似现在机器学习那样庞大的科学体系。开普勒从第谷的大量资料中发现行星运动规律的历史,“啤酒和尿布” 的故事,从数据中发现的相关关系将替代因果关系的宣言,是数据挖掘理论高度和实际应用的背书,是数据挖掘实现企图心的见证。一山哪能容二虎,数据挖掘和机器学习正面撞上了。它们之间有很多重合的地方,如下图所示。在重合部分的分类、聚类和回归上,机器学习有高层次的理论分析,有高效的训练方法;在非重合部分,机器学习有很多数据挖掘没有的东西,比如学习理论和强化学习。在机器学习崛起的背景下,我们很难说清楚数据挖掘区别于机器学习的独特价值是什么了。历史给机器学习加冕。
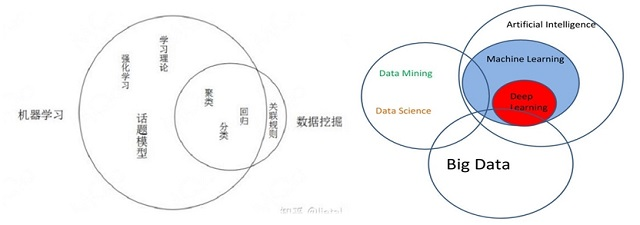
数据挖掘是偏数据分析师干的活,机器学习是偏算法工程师干的活。
数据而言,传统的数据挖掘数据量并不大,只有几万几十万这样,特征也不那么多,几百几千个维度差不多了,很多年前的教材讲的都是啤酒尿布啦欺诈识别啦预测和识别啦聚类啦这些脱胎于统计学的东西,上大数据集的性能么可想而知。
对于机器学习,数据分分钟以亿计算,特征以万维计算,比如广告的以几万个商品id为特征,自然语言的以单个词语作为向量特征来做训练,卷积神经网络的不知道多少个数据点了,艾玛,要输入图片里像素几千万个格子的值??围棋博弈的数据甚至可以自己和自己博弈产生天量数据,不需要你输入数据集,这叫强化学习。
算法而言,大多数时候,数据挖掘项目能用到关联 聚类 分类 回归 几类算法就不错了,偶尔用最拿衣服的神经网络,机器学习算法比这个多而复杂,特别神经网络类的模型感觉挺牛的,还涉及到很多算法开发的工作,新的成果层出不穷。
最后工作从工作量来看,数据挖掘的项目很多70%是在做数据的清洗,探索和分析,比如欺诈识别,时间序列预测,多维尺度分析,聚类,因子分析,更偏向于业务洞察,机器学习呢,也许同样很多数据清洗的工作,但它的很多像广告ctr预估 nlp挖掘 围棋博弈 视觉识别 都偏工程和数学。工作思路来看,数据挖掘会更喜欢业务应用决策辅助之类,很多时候是统计型的思路,调模型的时候喜欢基于业务洞察做小而美的特征组合啊区间缩放之类,机器学习我们看做的都是,加大数据量,把神经网络层数增加,给神经网络加一个逻辑门,给改成wide&deep,ctr的函数改成别的数学度量,文本距离改一下公式,文本的贝叶斯topic模型改一下,前面套一个蒙特卡洛模型马尔科夫模型之类,需要很多工程开发和数学的应用,但慢慢数据量上来了,神经网络(什么强化学习 迁移学习 卷积神经网络等)基本都要霸占了这个机器学习领域了。
原文链接: https://www.zhihu.com/question/20954873/answer/67031089





